Título: Stellar classification from single-band imaging using machine learning
Autores: T. Kuntzer, M. Tewes & F. Courbin
Institución del primer autor: Laboratoire d’astrophysique, École Polytechnique Fédérale de Lausanne (EPFL)
Estado: Publicada en Astronomy & Astrophysics, open access
Astrobites original: Teaching Stellar Classification to Computers
Una de las propiedades fundamentales de una estrella es su temperatura efectiva, la cual los astrónomos observacionales tienden a expresar en término del tipo espectral o color de la estrella. Una estrella caliente de clase O, por ejemplo, emite más luz a longitudes de onda más cortas, lo que la hace más azul que una estrella más fría de clase G o M (en términos espectrales). Idealmente, el tipo espectral de una estrella se determina mediante un espectro de alta resolución. El siguiente paso sería conocer su brillo en al menos unas pocas longitudes de onda diferentes. Para una muestra grande de estrellas, este método (fotometría multi-banda) es usualmente lo más eficiente. Pareciera ser intuitivo, pero los autores del artículo de hoy muestran que bajo ciertas condiciones, el tipo espectral de una estrella también puede ser determinado por una imagen en una sola banda fotométrica, usando técnicas de aprendizaje de máquinas supervisado, más conocido como machine learning, por su nombre en inglés.
Cómo funciona
Hay un efecto sutil que hace que las estrellas con diferentes espectros aparezcan sólo ligeramente distintas. Cada estrella es una fuente puntual de luz, que cuando se observa con un telescopio produce un patrón de difracción llamada función de propagación de puntos (PSF, por sus siglas en inglés). Pero la PSF cambia con la longitud de onda, por lo que la forma exacta de la imagen de una estrella depende de las características tanto del perfil de transmisión instrumental como del espectro de la estrella, en una manera un tanto complicada (Figura 1). Mientras más ancho es el rango de longitud de onda accesible, estas diferencias serán más grandes. Sin embargo, para poder explotarlas, es necesario obtener imágenes nítidas (limitadas por difracción) bajo condiciones extremadamente estables. Es por esto que los autores prueban su método principalmente en datos simulados que Euclid, un telescopio espacial de próxima generación, se espera que entregue, aunque el mismo método podría ser aplicado al Telescopio Espacial Hubble.

Figura 1: Imágenes simuladas de estrellas con diferentes tipos espectrales y, en la segunda fila, las diferencias pequeñas pero significativas entre esas imágenes (Figura 1 en el artículo, A&A 591, A54, 2016).
Para clasificar una estrella en la práctica es necesario pre-procesar y simplificar los datos primero. Los autores escogen un procedimiento llamado análisis de componentes principales para reducir una imagen pequeña de cada estrella en una serie de números que describen un punto en un «espacio de características» (o feature space, en inglés), una representación en menos dimensiones de la imagen en cuestión. En esta representación, el valor en cada dimensión corresponde a la fuerza de una diferencia particular en la forma de la PSF.
En un próximo paso, los autores entrenan una red neuronal artificial para encontrar un mapeo óptimo entre esos puntos en el espacio de características y los diferentes tipos espectrales. El set de datos a utilizar para este propósito debería ser grande, y debería contener sólo imágenes de alta calidad de estrellas con tipos espectrales ya conocidos. En principio, es posible compilar un set de entrenamiento a partir de datos simulados de manera realista, o bien a partir de imágenes reales y observaciones espectroscópicas. Finalmente, la red entrenada puede ser usada para estimar el tipo espectral de una estrella a partir de una imagen dada.
La idea fundamental detrás de usar una red neuronal para tareas de clasificación es poder generar automáticamente un modelo grande pero fundamentalmente simple, en vez de tratar de construir un modelo muy complejo de forma manual. Sin embargo, el reto está en optimizar un gran número de parámetros de modelos en un tiempo razonable, tratando de evitar sobre-ajustar o sub-ajustar estos parámetros. Esto generalmente requiere algo de experimentación y los autores también mencionan otros algoritmos viables para esta tarea, como por ejemplo el random forest.
Una prueba de concepto
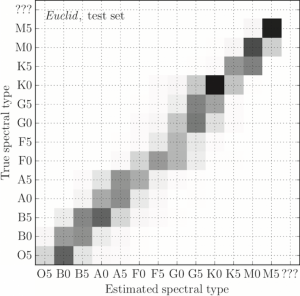
Figura 2: Una matriz de confusión que muestra el desempeño de un algoritmo de machine learning para clasificar estrellas, basado en datos simulados pero realistas de Euclid. Un clasificador perfecto debería producir una diagonal fina en este gráfico. La etiqueta ‘???’ se asigna a objetos que no son estrellas o a imágenes que no pudieron ser clasificadas (Figura 8 en el artículo A&A 591, A54, 2016).
Funciona! La red neuronal, entrenada apropiadamente en los datos simulados de Euclid, parece ser muy exitosa en clasificar estrellas en la secuencia principal. Un gráfico útil para verificar los resultados es la matriz de confusión (Figura 2), la cual muestra la desviación entre los tipos espectrales estimados y originales en las estrellas en el set de entrenamiento. El error típico en la predicción no es más que medio tipo espectral. Interesantemente, la mayoría de los errores ocurren en el caso de estrellas de tipo G y K, debido a la similitud de sus espectros. La clasificación de estrellas más rojas es en general más exitosa.
Más importantemente, los autores han demostrado que la clasificación estelar basada en una sola imagen de banda-ancha es feasible. La clasificación prueba ser confiable bajo la presencia de ruido y robusta contra complicaciones astrofísicas como extinción interestelar u objetos compañeros. El desempeño del algoritmo en el mundo real aún debe ser probado cuando Euclid sea lanzado (no antes del 2020), pero las técnicas de machine learning ciertamente permitirán una rápida clasificación inicial, incluso para estrellas débiles que de otra manera nunca podrían ser clasificadas.
Este artículo nos muestra que métodos computacionales avanzados como el machine learning pueden entregar información valiosa cuando se aplican a sets de datos astronómicos, algunas veces en maneras que no han sido anticipadas.
Comentarios
Trackbacks/Pingbacks
Pingback: ¿UFOs y quasares? | Astrobites en español - 20/01/2018