Título: Fast Radio Burst 121102 Pulse Detection and Periodicity: A Machine Learning Approach
Autores: Yunfan Gerry Zhang, Vishal Gajjar, Griffin Foster, Andrew Siemion, James Cordes, Casey Law, Yu Wang.
Institución del primer autor: Dept. of Astronomy, University of California Berkeley
Estado: Submitted to ApJ, open access.
Astrobite original: Teaching Machines to find Fast Radio Bursts por Joshya Kerrigan.

El astrobito de hoy combina dos temas fascinantes e independientes debido a un resultado muy importante: el aprendizaje automático y los estallidos rápidos de radio (FRBs, por sus siglas en inglés, N. del T.). El campo del aprendizaje automático se está moviendo a un ritmo sin precedentes con nuevos resultados fascinantes. Los FRBs tienen un origen completamente desconocido y se están preparando experimentos para detectar más de ellos. Así que vamos al grano y echemos un vistazo a cómo los autores del artículo de hoy lograron que una máquina identifique estallidos rápidos de radio.
Redes Neurológicas convolucionales
Comencemos presentando la técnica y la maquinaria que los autores utilizaron para encontrar estas señales. El campo del aprendizaje automático (machine learning en inglés, N. del T.) es excepcionalmente candente en este momento, y con nuevo conocimiento siendo introducido casi a diario en los mejores algoritmos de aprendizaje automático, la difusión a los campos cercanos se está acelerando. Esto no es, por supuesto, una excepción para la astronomía (de radio o de otro tipo), donde los conjuntos de datos crecen para ser extraordinariamente grandes e intratables para los algoritmos clásicos. Te presento a la red neuronal convolucional (CNN, por sus siglas en inglés, N. del T.), el algoritmo de aprendizaje automático más frecuentemente utilizado para el entendimiento y la predicción de datos con características espaciales (o sea imágenes).
¿Y cómo trabaja uno de estos algoritmos? Bueno, un punto de partida básico sería el de la red neuronal tradicional, pero le dejaré esa explicación a alguien más. Una red neuronal puede tomar tanto unos pocos como muchos parámetros de entrada, los que no necesariamente tienen que estar espacialmente relacionados unos con otros, lo opuesto a una CNN, la cual es muy adecuada para imágenes. (Nota: también puedes tener CNNs 1d o 3d). Estas imágenes, por supuesto tienen características, aquellas que cuando se combinan son importantes para identificar qué hay en la imagen. Toma por ejemplo la figura 1: un perro tiene características tales como orejas caídas, o una gran boca con una lengua protuberante. Una CNN aprende parte de todas estas características a partir de un conjunto de datos de entrenamiento que se le proveen, con una verdad asentada. En el caso de la figura 1, la predicción puede ser un perro, un gato, un león o un pájaro. Estas características se aprenden variando las escalas espaciales conforme las imagenes provistas son sucesivamente convolucionadas y la predicción se compara a su descripción conocida con cualquier corrección propagada hacia atrás para actualizar esas características. Este último paso es la parte del entrenamiento, la cual como podrás notar, es el mismo proceso que en una red neuronal no convolucional. Entonces, armados con este flamante y rápido clasificador, podemos movernos hacia un entendimiento de qué es lo que estaremos prediciendo.
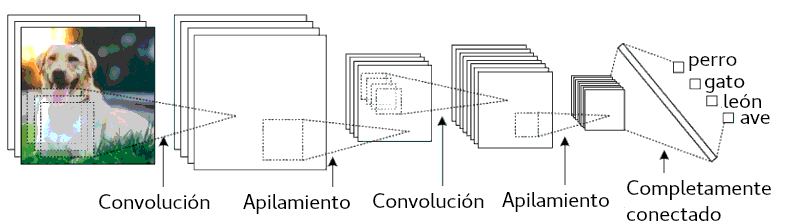
Figura 1. Un ejemplo de red neuronal convolucional. Una imagen de entrada es convolucionada secuencialmente a través de varias capas convolucionales, donde cada capa sucesiva aprende rasgos únicos, que tras entrenar, son finalmente utilizados para hacer una predicción basada en un conjunto de etiquetas. Adaptado de: https://www.kdnuggets.com/2018/06/topological-data-analysis-convolutional-neural-networks.html.
Estallidos rápidos de radio
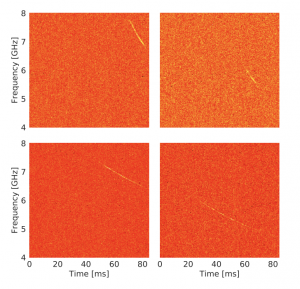
Figura 2. Pulsos de FRB simulados en los datos de tiempo-frecuencia del GBT. Los pulsos se simulan con una variedad de parámetros con el propósito de hacer la CNN tan robusta como sea posible. Figura 1 del artículo.
Hemos cubierto los FRBs en otros astrobitos en el pasado(1,2 y 3), y con cada nueva publicación, parece que nos acercamos más y más a encontrar el origen de estas misteriosas señales de radio. Una introducción rápida a los FRBs es que son estallidos brillantes en radio que duran milisegundos, vistos en datos tiempo-frecuencia de radiotelescopios. Estos estallidos tienen características únicas que los distinguen de otras señales de radio y que serán importantes para entender cómo los autores desarrollaron un conjunto de datos de entrenamiento para las predicciones en el artículo. Estas características consisten en una medida de dispersión, tiempo de llegada (DM y TOA, respectivamente por sus siglas en inglés), amplitud y anchura de pulso (hay otras más, pero voy a resaltar estas como las características más importantes). La DM es una de las características más interesantes de un FRB, ya que es la que indica que las FRBs son cosmológicas. La DM se mide a partir de la dispersión de la señal en tiempo y frecuencia conforme viaja a través de un medio ionizado, que en este caso es el medio intergaláctico. Esto es la curva que se ve en la figura 2, la cual retrasa la señal a tiempos posteriores mientras se mueve hacia frecuencias más bajas. TOA es el momento en que la señal arribó en las observaciones, amplitud es la densidad de flujo de la señal y anchura de pulso es la anchura al 10% de la amplitud máxima.
Al usar todas estas características para definir un conjunto de datos de entrenamiento, los autores simularon muchos tipos diferentes de FRBs, todos con sus propios valores únicos. Esto es importante porque tener un conjunto de datos de entrenamiento grande y robusto significa que es más probable que la red neuronal sea capaz de hacer predicciones robustas.
Poniendo la CNN a trabajar
Ahora tenemos todos los componentes: una red neuronal convolucional, un conjunto de datos de entrenamiento robusto y una cantidad monumental de datos del telescopio de Green Bank (GBT por sus siglas en inglés). Los autores buscan sondear los datos de archivo de la ahora bien conocida FRB 121102, la cual ha tenido un historial de ser una FRB repetitiva. Esto significa que FRB 121102 es un recurso sorprendente para entender los FRBs porque podemos tomar muchas mediciones.
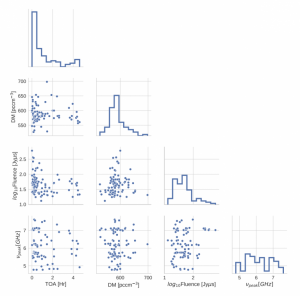
Figura 3. Distribución de los distintos parámetros de los pulsos de FRB 121102 descubiertos en el archivo de datos del GBT.Entender cómo estos parámetros se relacionan unos con otros puede darnos pistas de la naturaleza de FRB 121102. Figura 4 del artículo.
Utilizando muchas horas de datos de archivo del GBT, los autores pusieron a trabajar a la CNN, para predecir si se vería que hay pulsos adicionales de FRB de FRB 121102 que podrían no haberse notado debido a que la señal fue débil o simplemente haber pasado desapercibidos entre las grandes cantidades de datos. ¡Exitosamente encontraron 72 pulsos adicionales provenientes de FRB 121102! Y por si no fuera lo suficientemente interesante, más de la mitad de estos pulsos recién descubiertos ocurrieron dentro de la primera media hora del conjunto de datos. Esto da un conteo total, incluyendo las señales más viejas, de 93 puslos FRB.
La detección y medición adicional de estos pulsos es ciertamente importante. Como hemos dicho en otros astrobitos anteriores, el origen de estos estallidos es casi completamente especulativo y necesitamos conseguit tantas mediciones como podamos para descartar o restringir las potenciales fuentes cosmológicas. Tener un FRB repetitiva con la que empezar a recolectar datos, como las distribuciones de la figura 3, es fantástico para entender el ambiente de los FRBs que debería afectar a estos parámetros. Siendo optimistas, con el continuo desarrollo de estas CNNs y otras técnicas de aprendizaje automático, veremos una explosión de detecciones de FRBs.
Comentarios
Aún no hay comentarios.